- AI/ML & Document Intelligence (OCR + LLM)
- MVP Development
- Microservice & API Architecture
- Backend Engineering (Node.js/Express)
- Data Engineering & Integrations
- QA & Test Automation
- DevOps & CI/CD
- Security & Compliance
- Pilot Rollout & Support
Real-time document validation and fraud scoring
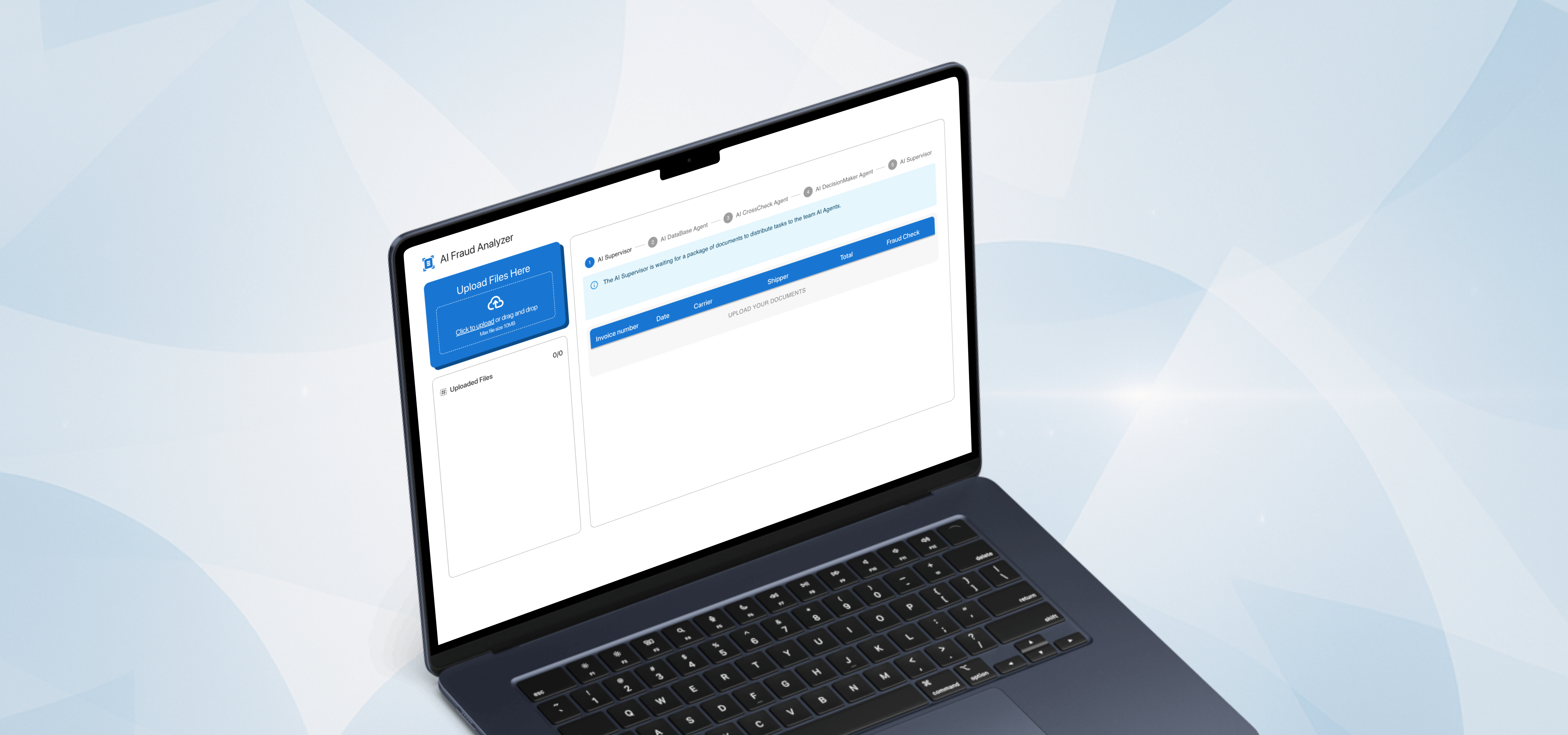
AI Fraud Detection for Freight Documents
A production-ready fraud detection engine that validates transportation document packages, extracts structured fields, and returns fraud scores in JSON. The service combines OCR (for coordinates), LLMs (for classification, extraction, and manipulation checks), and deterministic validations. It was deployed as an independent REST API with configurable rules per client and an admin layer for prompts and policies.
Industry
 AI
AIHeadquarters
 USA
USA
Services we provided
About the Client
A platform serving factoring companies, carriers, shippers, and brokers required automated, evidence-based document verification to reduce manual effort, expedite onboarding, and minimize payout disputes, without re-architecting their existing system.
Challenge
Manual review couldn’t keep pace with volume and variability in PDFs and scans. The team faced forged or altered values (e.g., rates), inconsistent data across documents, and missing artifacts (such as signatures/OS&D notes). Strict latency targets (≤ 30 seconds per document) and changing scope demanded a solution that handled Rate Confirmations and PODs first, produced structured JSON with confidence scores, and seamlessly integrated into current workflows.
Solution
-
Document preprocessing (PDF Worker Service)
We built a preprocessing layer that rotates/deskews pages, removes backgrounds, and enhances low-quality scans. Using a classic CV combined with Amazon Textract, the service enhances OCR fidelity, allowing downstream LLMs to “see” cleaner text.
-
LLM-powered classification & extraction
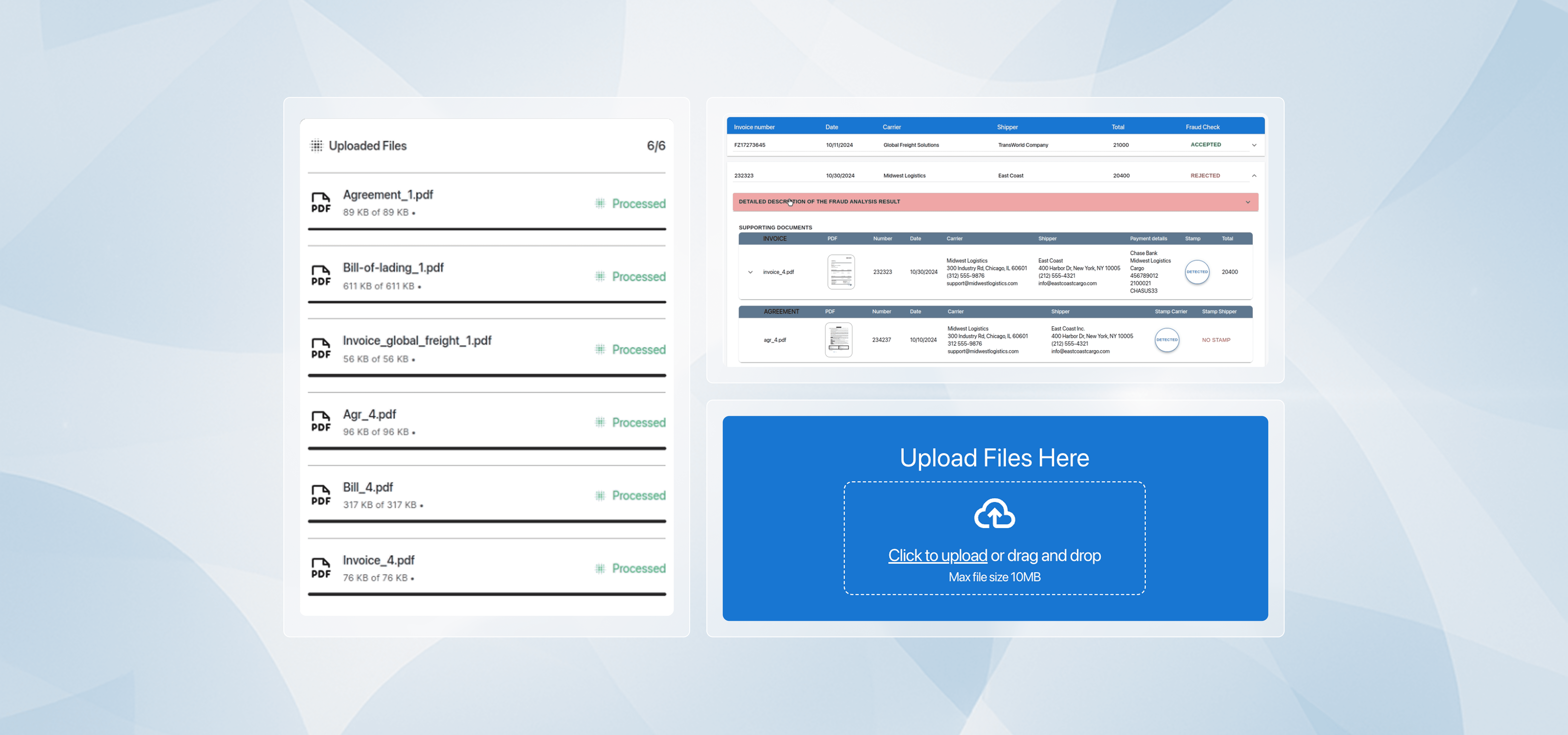
A multi-model flow classifies each file (Rate Confirmation, POD), then extracts payer, stops, line items, OS&D, and signatures. Each step returns structured JSON with rationales and confidence scores, making outcomes auditable.
-
Fraud analysis for values
Rate and totals fields are cropped using Textract coordinates, enhanced, and inspected for manipulations (replaced numerals, font anomalies, inconsistent arithmetic). The engine assigns a per-field fraud likelihood and highlights suspect regions.
-
Deterministic validation layer
Business rules check addresses, dates, prices, stop sequences, and cross-document consistency. JSON schema validation runs after every LLM step to ensure predictable outputs.
-
Observability & testing
Full LLM tracing (requests, tokens, latencies) and load tests on real samples harden quality and help operations spot regressions early.
Features delivered
-
AI-based parsing & field extraction
Semi-structured PDFs and images are converted into clean, JSON-enriched, concise explanations, ready for downstream automation.
-
Signature & OS&D validation (POD)
Detects presence and readability of signatures, scans for handwritten OS&D notes, and flags missing or suspicious confirmations at delivery.
-
Rate manipulation detection
Surfaces altered numerals, mismatched fonts/sizes, and inconsistent totals or line items; links every alert to exact on-page regions for quick review.
-
Timestamp & stop comparison
Verifies pickup/delivery windows and stop order; checks alignment between Rate Confirmation and POD to catch impossible sequences.
-
JSON fraud scoring output
Produces clear per-field and per-document validity/fraud scores with confidence levels, allowing systems or humans to triage instantly.
-
Scalable microservice
Stateless by design and ready to extend with new doc types or telemetry feeds in later phases.
Key results and business value
-
~20s average processing time (≤30s SLA)
Meets throughput targets for multi-page PDFs, enabling near-real-time decisions in factoring workflows.
-
90–95% extraction accuracy on quality docs
Reliable automation eliminates manual re-entry and reduces the need for back-and-forth communication with carriers and brokers.
-
80–85% accuracy on POD signature checks
Strong performance on noisy paperwork lowers dispute rates tied to delivery confirmation.
-
60–65% PDF quality improvement
Preprocessing boosts OCR/LLM accuracy and raises reviewer confidence in automated results.
-
Lower fraud exposure
Early detection of manipulated values and cross-doc mismatches curbs payout disputes and chargebacks.
-
Faster onboarding & scale
Automated verification accelerates client intake and absorbs volume growth without adding headcount.