

If you’re a regular reader of our blog, you probably know how much we love experimenting and solving challenges. This time, our task was connected with deep learning and text labeling.
Mastering the Challenge: Deep Learning for Text Multi-Labeling with Small Datasets
We needed to label sentences depending on the content. These texts were about three topics, and, hence, three labels:
- MANAGEMENT
- PAY&BENEFITS
- WORKPLACE
One sentence can have one or more labels.
Eg., for the sentence “I like this company, it’s a great and comfortable place to work in, but I want a bigger salary” the labels will be: PAY&BENEFITS and WORKPLACE.
There are some good services the API of which we could use for this kind of tasks, like Google Cloud NLP. But while it’s good at what it does, the service has a limited predefined labels list (categories), and its categorization starts after 20 words. Plus, it’s not free. But it does support multi-language (with which we will experiment in the next article).
The Options
So, we needed to develop a service of our own.
We had a list of labels and an unlabeled dataset of a specific domain (we wanted to do this multi-labeling in a specific domain). We didn’t have a labeled dataset. Oh, and we needed to make multi-labeling in English (for starters).
You can’t write and train a neural network without a labeled dataset, as there will be nothing to learn from. So, we were looking at transfer learning. This means taking a pre-trained model and training it on the last layers that regard to our task. But we still wouldn’t have a labeled dataset, even with 1-2K samples (it’s a micro dataset).
We had the state-of-the-art BERT available, but it was too big and took up a lot of resources during training and prediction.
Luckily, I found fast.ai, and we went with it. BTW, it works with both CPU and GPU. Their approach is ULMFiT, and here is what it means:
- They train a language model on a large dataset (Stephen Merity’s Wikitext 103 dataset, which contains a large pre-processed subset of the English Wikipedia)
- Fine-tuning the language model on a smaller, not labeled (specific domain) dataset.
- Fine-tuning the classifier to a specific task using a small dataset with just100 samples.
Here’s what they say:
“On one text classification dataset with two classes, we found that training our approach with only 100 labeled examples (and giving it access to about 50,000 unlabeled examples), we were able to achieve the same performance as training a model from scratch with 10,000 labeled examples.”
Click here to read more about ULMFiT.
The Process
Here’s a link to my Jupyter notebook.
We used 3K not labeled samples and 120 labeled ones.
We experimented on the Kaggle Notebook with GPU.
NOTE! If you found a small dataset labeled by someone on the internet, at least take a quick scan to see if it’s labeled more or less properly. This was my first mistake: I spent several days trying to figure out why my model predicted so poorly. After that, I spent just two hours making my own dataset for 120 labeled samples.
The Coding
Phew! Now, there will be fewer words, more code.
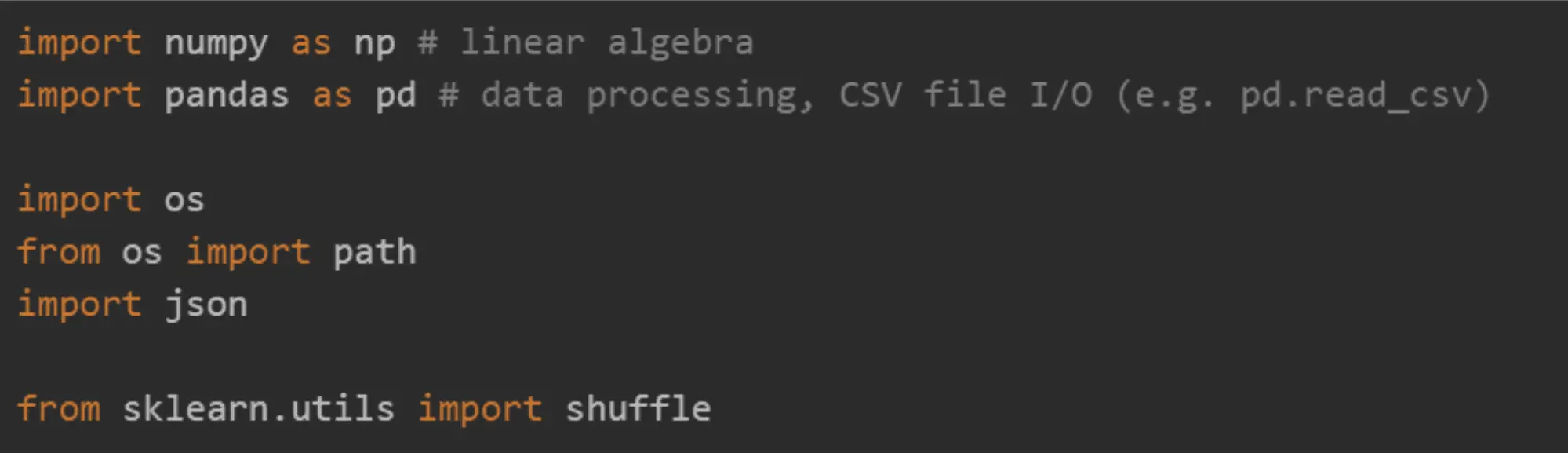
IMPORT dependencies:
Declare constants:
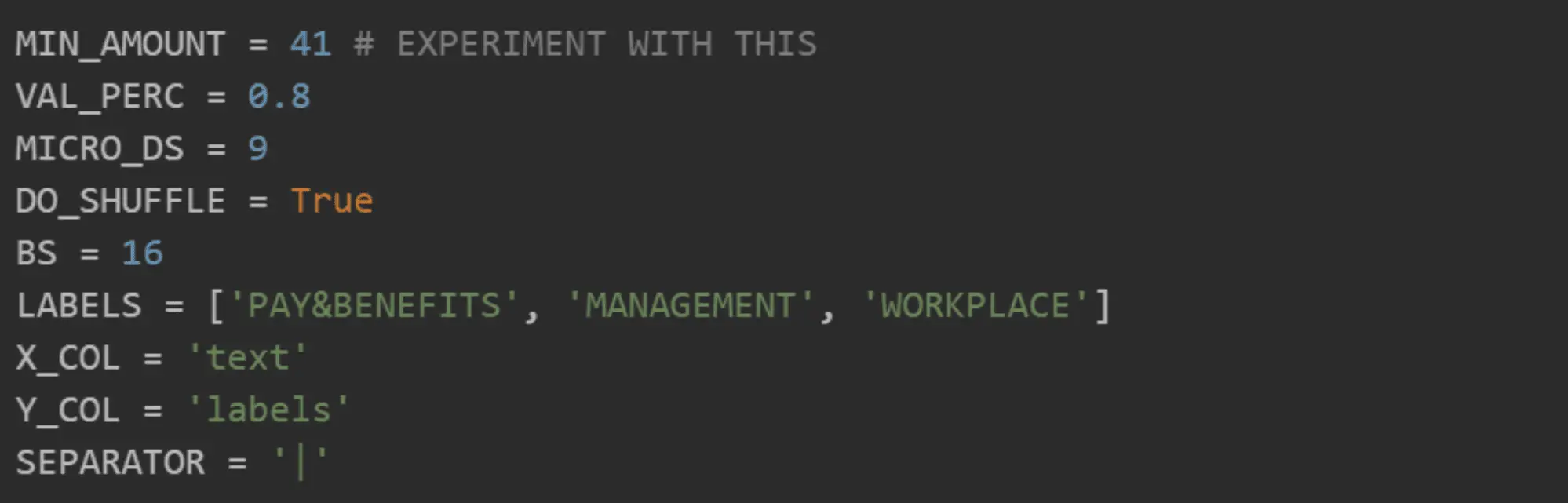
We have two datasets: a bigger dataset for the language model, and a smaller one for the classifier.
Load LM dataset:

Normalize the dataset as it is in JSON:
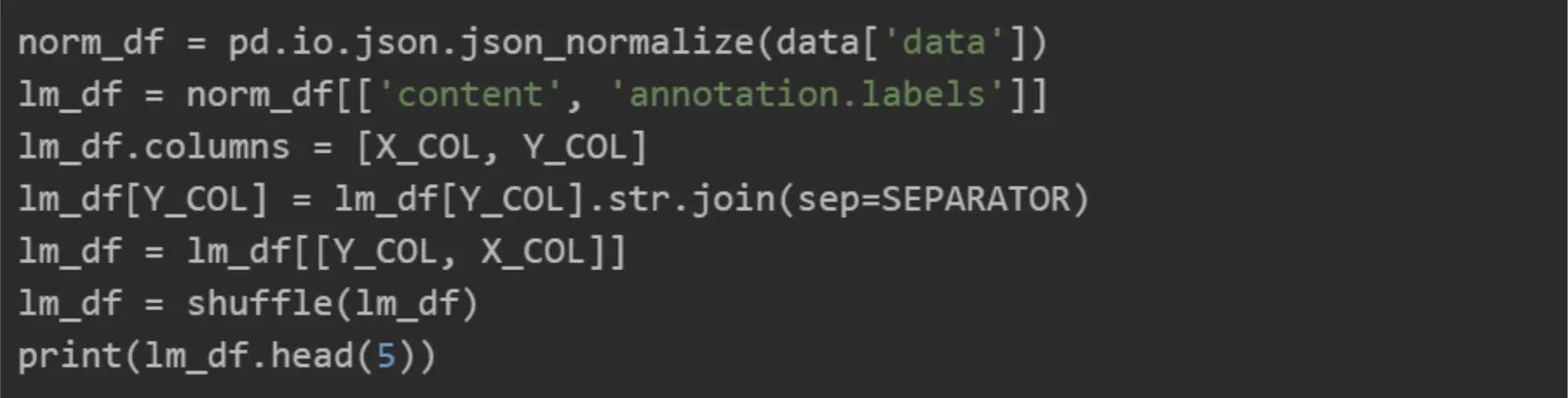
NOTE: We will experiment only with three labels from the dataset, as it takes time to label the dataset thoroughly, and this article is meant to show you the approach, not how to reach 99% accuracy for production.
The dataset has 3475 items:

Load the dataset for classifier (csv):

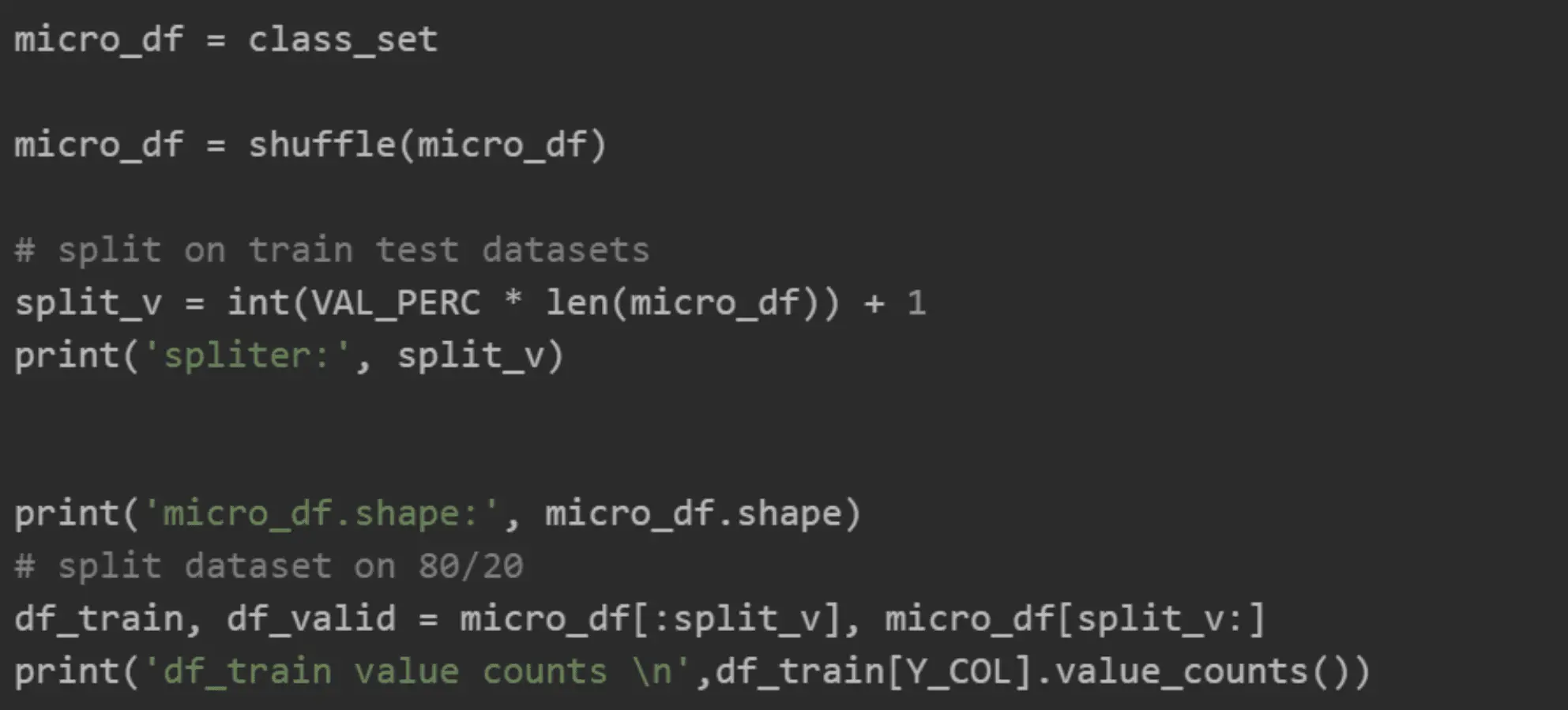
Split and shuffle the dataset:
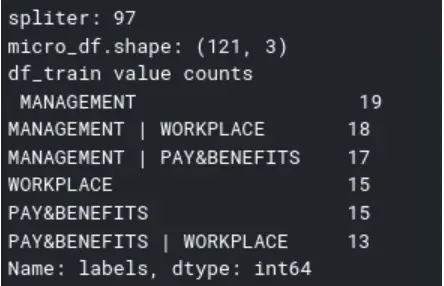
Fast.ai requires a databunch to train the LM and the classifier.
Create an LM databunch:

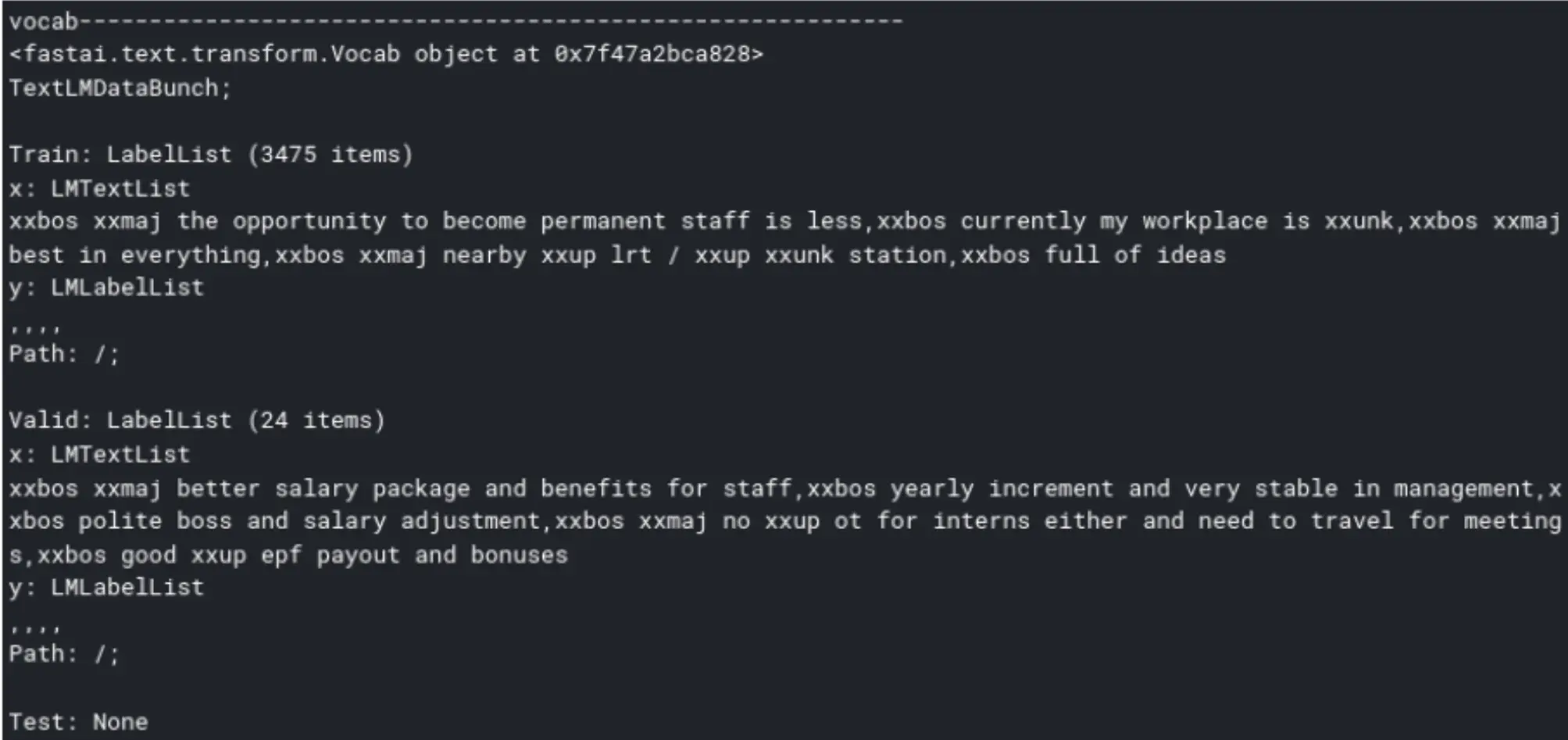
We can see several tags applied to the words, as shown above. This was done to leave all the information that can be used to understand the new task’s vocabulary. All the punctuation, hashtags and special characters are also left. The text is encoded with various tokens:
- xxbos. Beginning of a sentence
- xxfld. Represents separate parts of a document like title, summary, etc. Each one will get a separate field, that’s why they will be numbered (e.g., xxfld 1, xxfld 2).
- xxup. If there's something in all caps, it gets lower-cased and a token called xxup will get added to it. Words that are fully capitalized, such as “I AM SHOUTING”, are tokenized as “xxup i xxup am xxup shouting.”
- xxunk. The token is used instead of an uncommon word.
- xxmaj. The token indicates that there is capitalization of a word. “The” will be tokenized as “xxmaj the.”
- xxrep. The token indicates a repeated word. If you have 29 ! in a row, it’s xxrep 29 !.
Let's take a look at what we have:


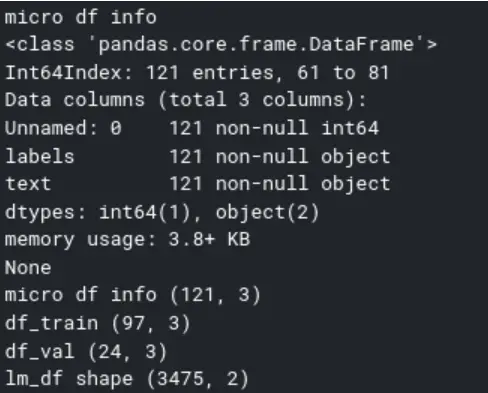
Create a databunch for the classifier:
Replace the label delimiter ';' with a single character '|' to allow compatibility with fast.ai 1.0.28
Let’s see what we have in this databunch:


Create an LM learner:

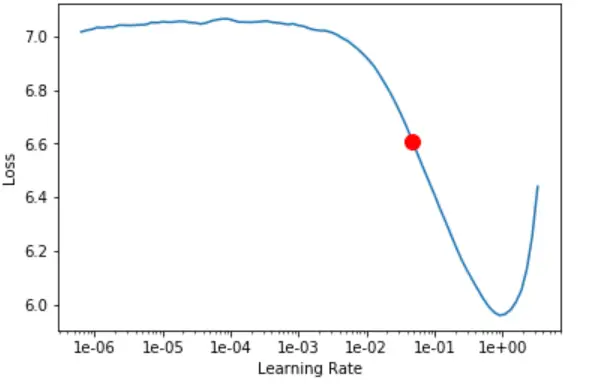
Train the LM:
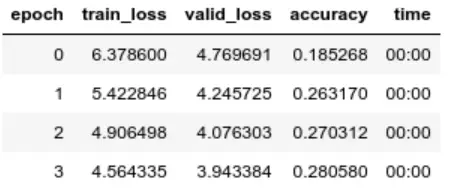
Let’s see how the LM fits our domain. We’ll make it generate the next 100 logical words:


Not too shabby… There’s even some thought in it.
Final step — build the Classifier-learner:

Let’s see the suggestion for the learning rate for training:

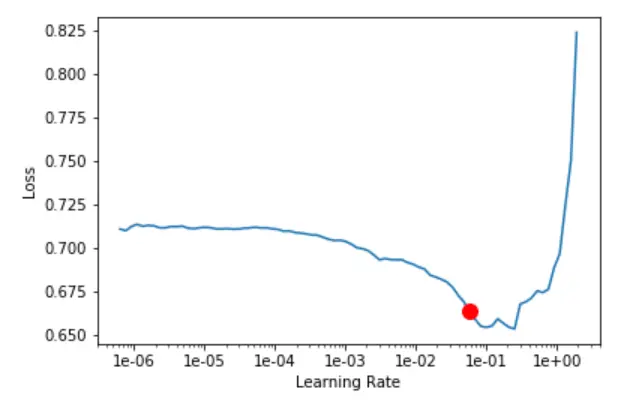
Let’s train the classifier:
DONE!
Let’s see what we have. Look at the prediction and learning history (compare the target and the prediction):
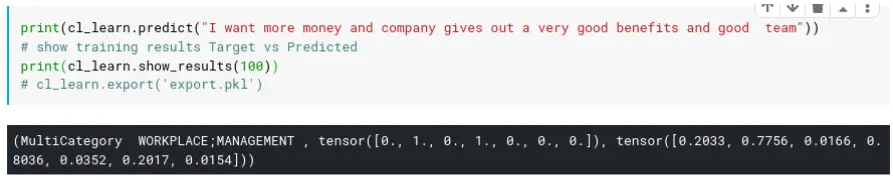
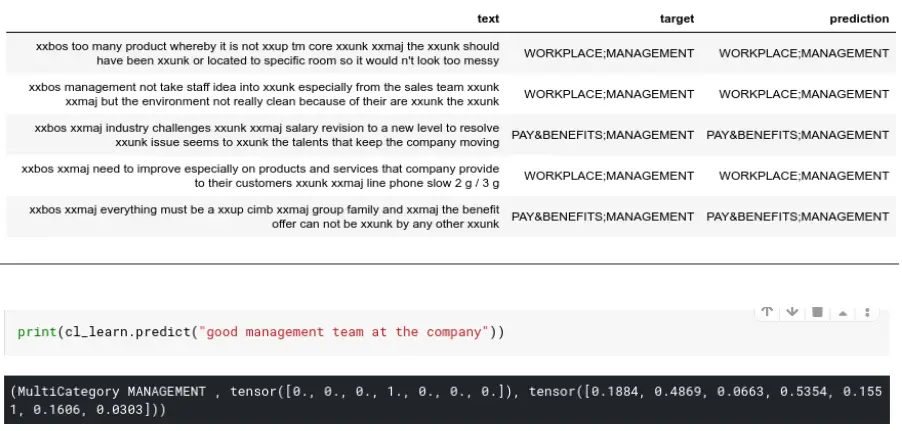
The Result
I’d say it’s not a bad result for 120 labeled data pieces, 80% of which was used for training the classifier. Of course, if we’re talking about production, it will need improvement in data pre-processing, learning stages configuration, and so on. But the main idea is that by using fast.ai, we can build a text classifier with a couple thousand not labeled and only 100 labeled data pieces.
Our next steps would be to:
apply this case to other languages using MULTIFit
try multi-tasks with fast.ai
experiment with BERT on more complex tasks.
Stay tuned for our next articles!